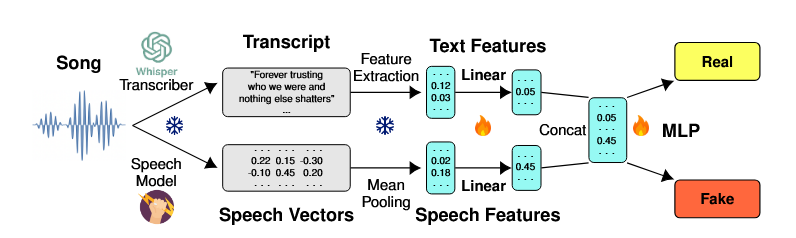
Abstract
The rapid advancement of AI-based music generation tools is revolutionizing the music industry but also posing challenges to artists, copyright holders, and providers alike. This necessitates reliable methods for detecting such AI-generated content. However, existing detectors, relying on either audio or lyrics, face key practical limitations: audio-based detectors fail to generalize to new or unseen generators and are vulnerable to audio perturbations; lyrics-based methods require cleanly formatted and accurate lyrics, unavailable in practice. To overcome these limitations, we propose a novel, practically grounded approach: a multimodal, modular late-fusion pipeline that combines automatically transcribed sung lyrics and speech features capturing lyrics related information within the audio. By relying on lyrical aspects directly from audio, our method enhances robustness, mitigates susceptibility to low-level artifacts, and enables practical applicability. Experiments show that our method, DE-detect, outperforms existing lyrics-based detectors while also being more robust to audio perturbations. Thus, it offers an effective, robust solution for detecting AI-generated music in real-world scenarios. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
Citation
Markus Frohmann,
Gabriel Meseguer Brocal,
Markus
Schedl,
Elena V. Epure
Double Entendre: Robust Audio-Based AI-Generated Lyrics Detection via Multi-View Fusion
Findings of the Association for Computational Linguistics: ACL 2025, 2025.
BibTeX
@inproceedings{MarkusFrohmann2025LyrDetec,
title = {Double Entendre: Robust Audio-Based AI-Generated Lyrics Detection via Multi-View Fusion},
author = {Markus Frohmann and Gabriel Meseguer Brocal and Schedl, Markus and Elena V. Epure},
booktitle = {Findings of the Association for Computational Linguistics: ACL 2025},
year = {2025}
}