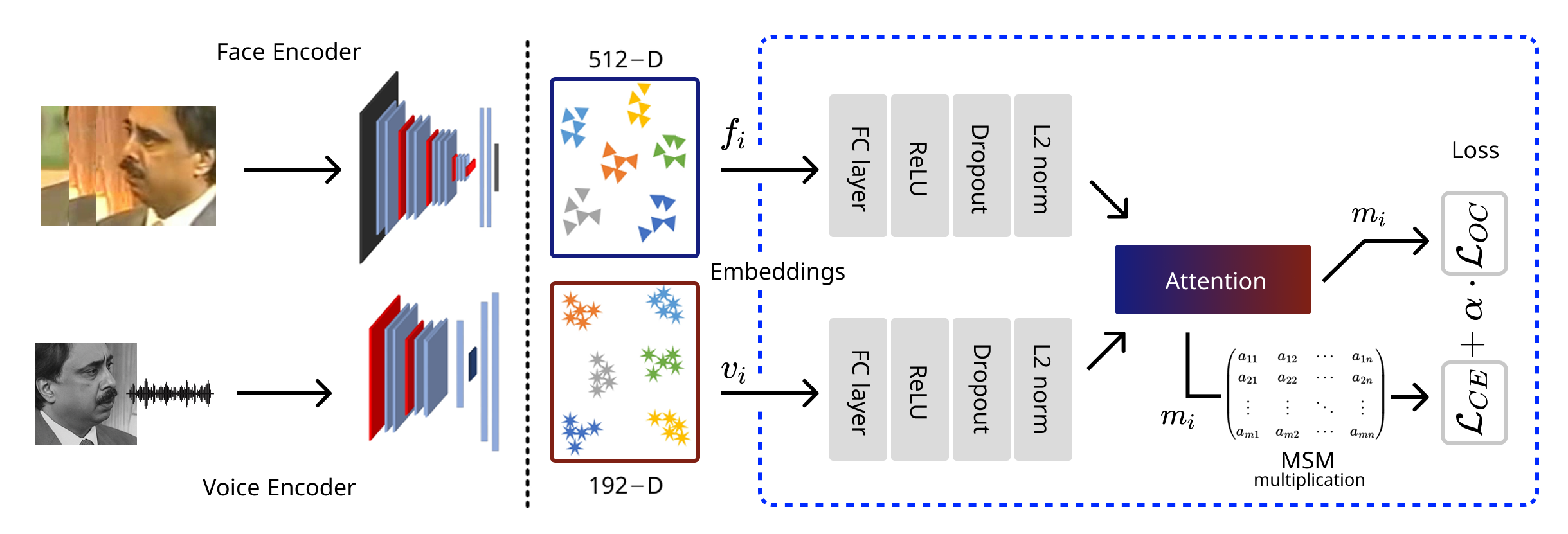
Abstract
Face-voice association is widely studied in multimodal learning and is approached representing faces and voices with embeddings that are close for a same person and well separated from those of others. Previous work achieved this with loss functions. Recent advancements in classification have shown that the discriminative ability of embeddings can be strengthened by imposing maximum class separation as inductive bias. This technique has never been used in the domain of face-voice association, and this work aims at filling this gap. More specifically, we develop a method for face-voice association that imposes maximum class separation among multimodal representations of different speakers as an inductive bias. Through quantitative experiments we demonstrate the effectiveness of our approach, showing that it achieves SOTA performance on two task formulation of face-voice association. Furthermore, we carry out an ablation study to show that imposing inductive bias is most effective when combined with losses for inter-class orthogonality. To the best of our knowledge, this work is the first that applies and demonstrates the effectiveness of maximum class separation as an inductive bias in multimodal learning; it hence paves the way to establish a new paradigm.
Citation
Marta
Moscati,
Oleksandr Kats,
Mubashir Noman,
Muhammad Zaigham Zaheer,
Yufang Hou,
Markus
Schedl,
Shah
Nawaz
Face-Voice Association with Inductive Bias for \Maximum Class Separation
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),, 2026.
BibTeX
@inproceedings{Moscati2026MSM,
title = {Face-Voice Association with Inductive Bias for \Maximum Class Separation},
author = {Moscati, Marta and Kats, Oleksandr and Noman, Mubashir and Zaigham Zaheer, Muhammad and Hou, Yufang and Schedl, Markus and Nawaz, Shah},
journal = {Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),},
booktitle = {Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),},
year = {2026},
year = {2026}
}